Deep Neural Networks for YouTube Recommendations
简介
这篇论文是Google出品的讲解YouTube中推荐算法的论文,整体上看工程意义可能要大于研究的意义,是一篇很好的讲解推荐系统、算法的综述。其中涉及到非常普遍的大规模推荐系统的工程实现方法以及对应的算法环节,从系统角度讲几乎任何推荐系统都脱离不了这个框架,在这个框架之上各种工程实现与算法实现分别从不同的角度调优这个系统。
以下我将简单的介绍一下这篇论文。
方法
架构
大规模推荐系统面临问题的规模是一个非常大的规模:从一个数以十亿、百亿级别的内容库中为数以亿记得用户推荐几十到几百个结果。任何传统的方法都不可能在一个非常短的时间内(<1s)完成这个工作的。在这个问题上业界做了多年的研究和探索,目前大家基本上是基于一个两阶段的召回 + 排序的架构去实现的。
解决如此大规模问题的一个重要的指标是响应时间,一个非常复杂的算法很难在短时间内完成如此多结果的计算,因此非常容易的可以想到一个折中方案:
- 从各个数据源非常快速的筛选出一批结果,顺序和精度不是很重要:这个阶段我们称之为召回
- 对上一步得到的结果(在数百到数千这个量级)进行非常精确的排序工作:这个阶段我们称之为排序
召回
召回一般会使用一些非常轻量级或者大部分运算可以再离线(offline)进行计算的方法,譬如矩阵分解:离线计算出内容的向量,在线通过一个向量索引系统来快速的搜索出与某个向量最相近的向量集合。更简单暴力的方法包括最热门,最新发布等等方法。
还有一类方式是使用推送的技术,当有新的可以推荐内容进入系统后立刻进行异步的推送计算,计算结果保存在一个存储系统中。当在线需要获得某个用户的推荐内容时,从这个存储系统中直接读取即可,相当于完全剥离了算法的计算和结果获取两个过程。(据我所知,至少Pinterest曾经使用/正在使用这个架构)
排序
排序阶段就是各家的必争之地了,因为待排序集合比较小,因此可以上一些非常重量级的算法来精细的调整结果。最常见的譬如点击率预估模型(CTR)一大类,协同过滤一大类,LTR一大类,最近几年又有更加复杂庞大的模型比如基于RNN的推荐算法,基于增强学习的推荐算法等等。
本文整体上也是基于这样的架构,整个系统分为两个过程,以下我将分别介绍这两个过程。
召回
——众里寻他千百度
上文已经解释了召回阶段的目标,那么本文中召回阶段被建模为了一个分类问题,其求解的目标是:
\[P(w_t = i|u, c) = softmax(v_iu)\]其中$u$表示用户,$c$表示一个上下文,$v_i$表示第$i$个推荐内容。基于上式如果我们能求解出所有$v$的结果并选择最大的一个,那么这个内容就是最佳的推荐内容。在机器学习领域这是一个非常常见的问题,接下来我们就要选择合适的输入特征以及网络结果来训练这个模型。
在本文的建模方法中,其分别计算了内容和用户的Embedding向量, 通过两个向量的内积来计算出两者的相关程度。因此这里有三个关键点:内容的Embedding矩阵训练、用户的Embedding矩阵训练以及两者的快速点积计算和筛选。
同时原文中特别强调了他们选择使用隐含反馈(譬如点赞、留言等等属于明确反馈,相反观看行为等属于隐含反馈),因为隐含反馈的数据更加丰富一些可以帮助他们解决长尾数据上的特征抽取问题。
模型架构
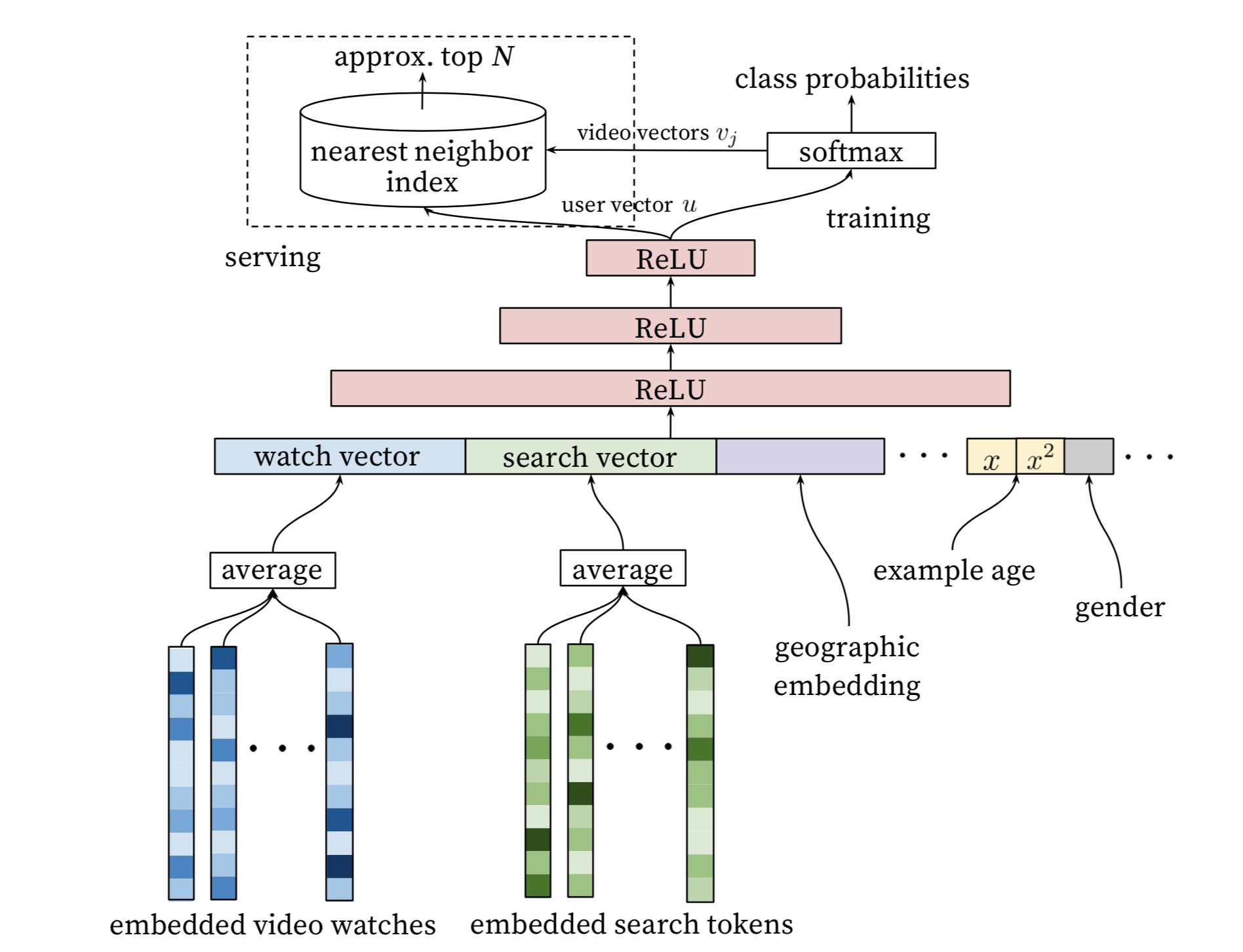
上图已经可以充分的解释模型架构了我就不赘述了,其中一些特点我接下来解释一下。
PS:需要说明的一点是,这个图里softmax的部分实际上省略了一个$256 * N$的大小的一个矩阵,其中$N$表示所有视频的数量。在后文中试验部分其补充说明了一下,并解释说这一层也可以看做是一种Embedding形式,而图中写入最近邻索引的数据就是这一个矩阵。
负采样优化
训练该模型的一个巨大的问题就是待分类的数量太大了,规模可以达到数十亿。训练这样大小的一个分类器如果不采用一些优化效率低并且效果也会有问题。
那么一个非常常见的优化就是对Label进行负采样。本文中Label实际上只有一个是Positive的其他全部都是0,那么对于0的Label每次训练可以不计算全部的Label而是随机的抽样一部分进行计算即可。
训练数据
文中花了大量的篇幅来描述训练数据是如何产生的,简单的说所有训练数据都来自于用户的观看记录(当然还包括用户的Profile数据),其在选择和使用用户观看数据上做了一些优化:
- 为每个用户生成相近数量的训练样本:这一步是为了防止系统在优化时过多的考虑了动作频繁的用户。
- 预测下一观看视频:给定一个用户的视频观看历史序列,有多种方式来建模这个目标(就如同NLP中给定一个句子建立语言模型时,有nGram、CBOW、SkipGram等等方法)。一种常见的做法是从一个序列片段(也可以是全部序列)中随机选择一个视频作为目标,其他视频作为输入。这种方法在训练数据集上可能会得到一个很好的拟合结果,但是因为其使用了当前时间之后的信息,也就是说假设预测目标是$v_t$其中$t$表示时间,那么在预测过程中实际上是使用了$t$时间之后的信息,但是在实际的使用过程中并没有这一部分信息,因此即使这样做会提高模型的拟合程度,我个人认为这仍然是一个相对不科学的方案。(这不同于NLP中的SkipGram之类的方法,因为在这个场景下在线预测时整句也是提供出来的)本文中使用的方法就是在用户观看的视频序列中选择一个视频作为目标后,只使用观看这个视频之前视频作为输入特征。
- 视频观看特征的顺序无关性:因为上一个特点模型使用的是预测下一个观看视频的建模方式,那么如果模型中考虑了过去视频的输入顺序有可能使得最近观看的视频对最终的结果造成过多的影响。虽然业界在长-短期兴趣的建模上有很多工作和成果,但是本文简单抛弃了观看视频的顺序特征。(Google在这里一定是夹带了私货没有写到论文里,以上诸多特点应该都有私货……)
Example-Age Trick
Example-Age的引入是期待得以解决模型偏向于推荐用户过去观看过的视频(这些视频当然更符合用户的个人兴趣爱好)而对新的视频不感冒,然后这并不是我们要达到的目的。因此其引入了一个Example-Age特征……之所以我加了Trick这个词是因为这个方法我觉得还是很Tricky的,虽然按照论文所述其效果是非常明显的。
Example-Age特征表示的是作为训练目标(Label)的视频的时间与整个训练集中最大的时间的差值,相当于在训练过程中告诉模型在其观测到一个指定的输入的时候时间距离现在有多久,那么对于一些时效性很强的视频其在Example-Age上获得的权重就比较大,而对于时效性不是很强属于一般兴趣的输入Example-Age上获得的权重就比较小。同时在学习的过程中模型也可以学习到在一定输入的情况下,其与Example-Age连续变化之间的关系。考虑一种极端的情况,假设有N个训练数据输入的内容是完全一致的除了Example-Age不同,那么模型会根据各个数据不同的Label学习到在一个指定的输入下,不同的 Example-Age对应的Label的变化。
当在线预测的时候这个特征设置为0或者是一个很小的负数来表示正在预测一个最近时间点(当前时间点)的内容。
在线召回
在线系统进行召回计算的时候系统期望得到的是一个视频的Top列表,而具体每个视频的概率是多少并不是很重要,因此实际上在线预测时softmax部分的计算是省略的,在上面的架构图中也是可以看到的。所以这个问题就转换成了从一个海量的向量库中找到某个给定向量的最近邻的问题,而这个问题业界是有很好的解决方案的。
所以在线召回的时候首先计算(或者从存储中读取计算好的)用户向量,也就是图上网络中最后一层 Relu的输出,然后在视频向量库中找到和该向量最相近的向量集合,该集合即是召回视频集合。
排序
排序阶段旨在对给定的小规模候选内容进行高级排序,使得结果的顺序更加合理。不同于召回阶段的优化目标,排序阶段的优化目标一般来说更加明确的指向用户的点击率、观看率、观看时间等等。
模型架构
![]()
上图写的也是比较清楚的,我在说明一下:
- Impression VideoID代表的就是要推荐的视频,Embedding之后输入网络
- Watched Video IDs代表用户最近观看的视频ID列表, Embedding之后计算了所有视频向量的平均值然后输入网络
- 输出函数是Sigmoid函数,采用CrossEntropy损失函数
这个网络架构没有特别多要强调的东西,不过其中包含了不少经验性质的东西,原文中也有描述:
- 虽然NN捕捉特征的能力比较强,但是相应的会对输入特征的变化过度的敏感,尤其是对于连续值特征。所以一方面,人工特征工程的工作并不能完全的被替代,而且对一个特征进行不同的变换和规范化之后同时输入网络会对网络的稳定性起到积极的作用。所以上图中可以看到Normalize部分对应的输入方法。其中$\tilde{x}$表示对$x$的分布从负无穷到$x$的积分。
- 视频的展现次数信息是比较重要的,尤其是当用户最近被推荐了某个视频之后并没有观看该视频,那么原则上模型是需要打压这样的结果的(当然这个问题不仅仅是这么简单,还存在一个后悔的概率)
训练目标和预测目标
网络的损失函数是非常好理解的,不过原文里这一部分做了一些优化,其对正样本的损失计算是加权的,加权的值就是该样本的观看时间,负样本全部给定单位权重。所以直观上讲,这个模型会对观看时间较长的视频有较高的倾向性。
原文中给出了该方法实际模拟的似然概率以及相应的简化,最终导出了上图中在线预测的公式,但是这块我并没有理解搬运如下:
\[odds(x) = \frac {\sum_{i=0}^{K} T_i} {N - K}\]其中$N$表示所有样本,$K$表示所有正样本,$T_i$表示第$i$个视频的观看时间。上式约等于:
\[E[T](1 + P)\]其中$P$表示点击概率,$E[T]$表示观看时间的期望。那么因为$P$通常是一个较小的数字因此可以与等于$E[T]$,那么在线服务的时候就使用$e^x$来作为最后的输出函数。
对于观看时间作为权重这一部分我个人有一些看法, 因为各个视频的长度并不同,因此直接使用时长对于不同视频并不公平。相应的如果使用观看视频时长与视频时长的比例作为权重可能更加合适。当然这个方法需要考虑特别短的短视频的权重如何处理。
总结
以上就是Google这篇论文的主要内容,我们可以看到其综合了算法和工程两方面的内容且更加偏向算法方面。很难说这篇文章中的方法就是目前应用最广、效果最好的方法,实际上在很多方面都有可以改进的空间并且已经有很多算法在这方面进行了深入的研究。
不过这篇文章仍然是一篇非常好的抛砖引玉的文章,无论是对于推荐系统算法的研究人员还是推荐系统工程的开发人员都是一个很好的Just Work的例子,有很好的借鉴和参考的意义。